
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
Liquid AI has released LFM2-Audio-1.5B, a compact audio fundamental model that can be understood and generated through a single end-to-end stack. It allows for low latency real-time assistants on resource-constrained devices, extending the LFM2 family to audio while retaining a small amount of footprint.
But what is it actually? A unified main chain with off-word audio I/O
lfm2-audio extends the 1.2b parameter LFM2 language skeleton to treat audio and text as first-class sequence tokens. What is crucial is the model Unlock Audio representation: The input is a continuous embedding projected directly from the original waveform block (~80 ms), while the output is discrete audio code. This avoids discrete artifacts on the input path while maintaining the way in which self-rotation is produced.
On the implementation side, published checkpoints use:
🚨 (recommended reading) Vipe (video posture engine): a powerful 3D video annotation tool for space AI
- backbone: LFM2 (Hybrid Conv + Note), 1.2B Parameters (LM only)
- Audio encoder: fastConformer (~115m, Canary-180m-flash)
- Audio decoder: RQ converter predicts discrete Boobs Codec Token (8 code books)
- context: 32,768 tokens; vocabulary: 65,536 (text) / 2049×8 (audio)
- accurate: Bfloat16; license: LFM Open License v1.0; language: English
The two-generation model of real-time agents
- The generation of intertwined For live, voice-to-voice chat, the model can alternate text and audio tokens to minimize perceived latency.
- Generate in sequence Used for ASR/TTS (switching method turns one by one).
Liquid AI provides Python package (liquid-audio) and a Gradio demonstration that reproduces these behaviors.
Delay: <100 ms to the first audio
Liquid AI team reports end-to-end delay below 100ms From a 4-second audio query to the first auditory response (a proxy for perceived responsiveness in interactive use), it indicates that the model under its settings is faster than that of a model with a parameter smaller than 1.5B.
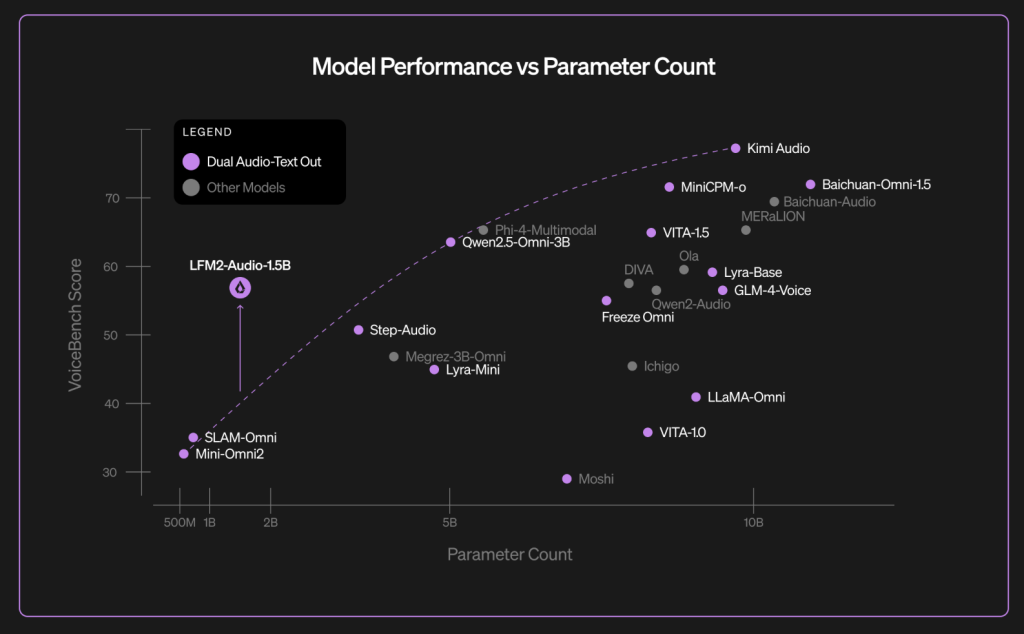
Benchmark: VoiceBench and ASR results
exist Voice desk– Nine audio-assisted evaluation kits – Liquefaction report Total score 56.78 For LFM2-Audio-1.5b, each task number is disclosed in the blog chart (e.g., Alpacaeval 3.71, Commoneval 3.49, Wildvoice 3.17). The liquid AI team compared with larger models such as QWEN2.5-OMNI-3B and MOSHI-7B in the same table. (VoiceBench is an external benchmark introduced in late 2024 for LLM-based voice assistants)
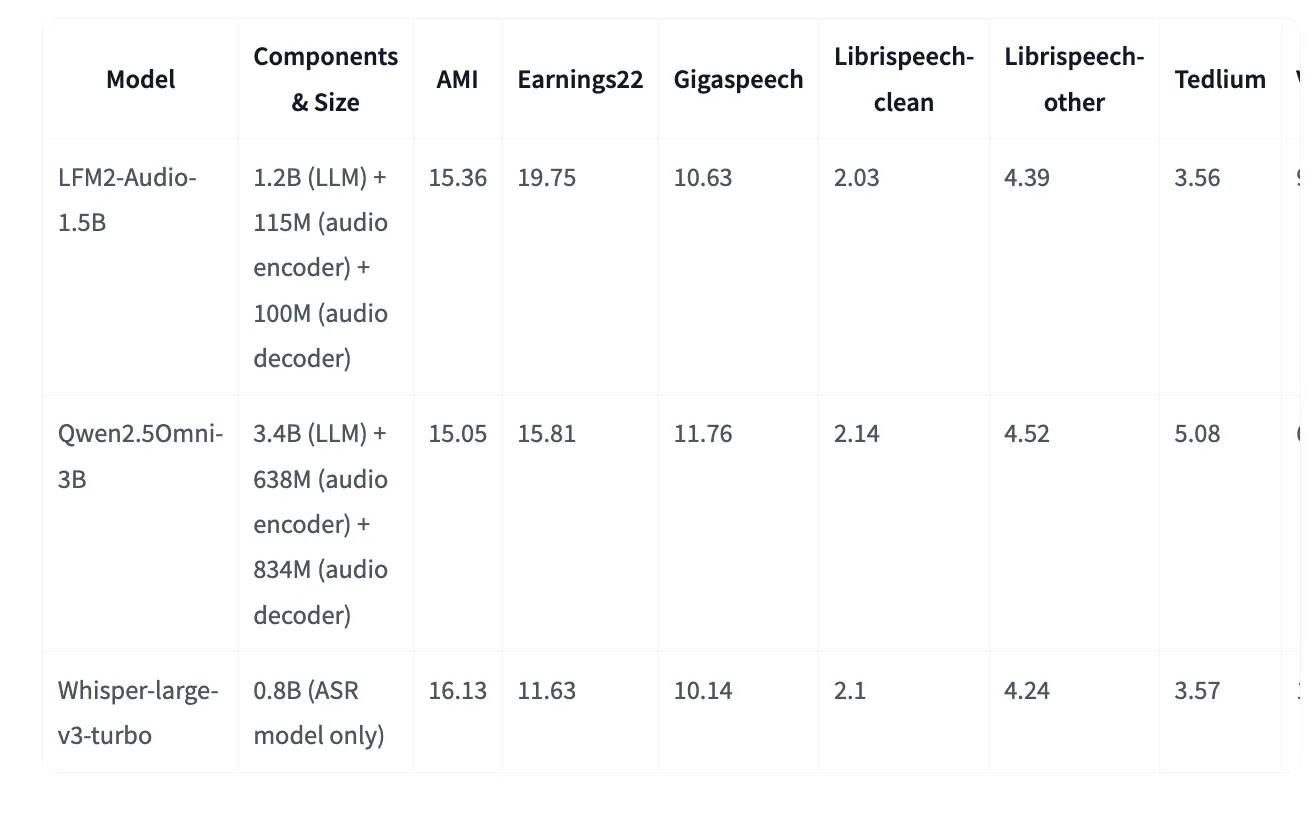
The model card on the face provides an additional voice board table (closely related to each task value (but not exactly the same) and includes classics ASR Although LFM2-audio matches or improves some datasets, whisper-large-v3-turbo is matched or improved on Whisper-V3-turbo. For example (lower is better): AMI 15.36 vs. 16.13 (Whisper-Large-large-V3-Turbo), Librispeech-Clean 2.03 vs. 2.10.
OK, but why is it really important in the voice AI trend?
Most “Omni” stack couples ASR → LLM → TTS, which adds latency and fragile interfaces. The single-back key design with continuous input embedding and discrete output code reduces glue logic and allows for intercom decoding for early audio transmission. For developers, this will translate into a simpler pipeline and faster perceived response time while still supporting a model of ASR, TTS, classification and conversational agents. Liquid AI provides code, demonstration entry point and distribution through hug surfaces.
Check Github page,,,,, Embrace Facial Model Card and Technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter. wait! Are you on the telegram? Now, you can also join us on Telegram.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥 (Recommended Reading) NVIDIA AI Open Source VIPE (Video Pose Engine): a powerful and universal 3D video annotation tool for spatial AI