
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
Is a single AI stack plan like a researcher’s plan, a reason on the scene, and a moving move across different robots – not re-read from scratch? Google DeepMind Gemini Robot Technology 1.5 Yes, by dividing the embodied intelligence into two models: Gemini Robot For advanced manifestation reasoning (space understanding, planning, progress/success estimation, tool usage) and Gemini Robot Technology 1.5 For low-level visual motion control. The system targets long horses, real-world tasks (e.g., multi-step packaging, waste classification with local rules) and introduces Movement transfer Reuse data across heterogeneous platforms.
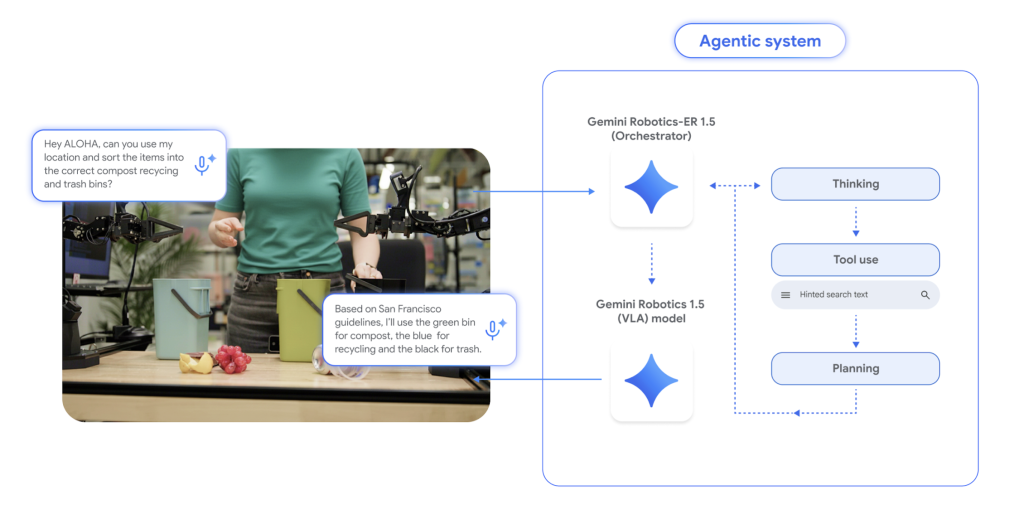
What is actually Stack?
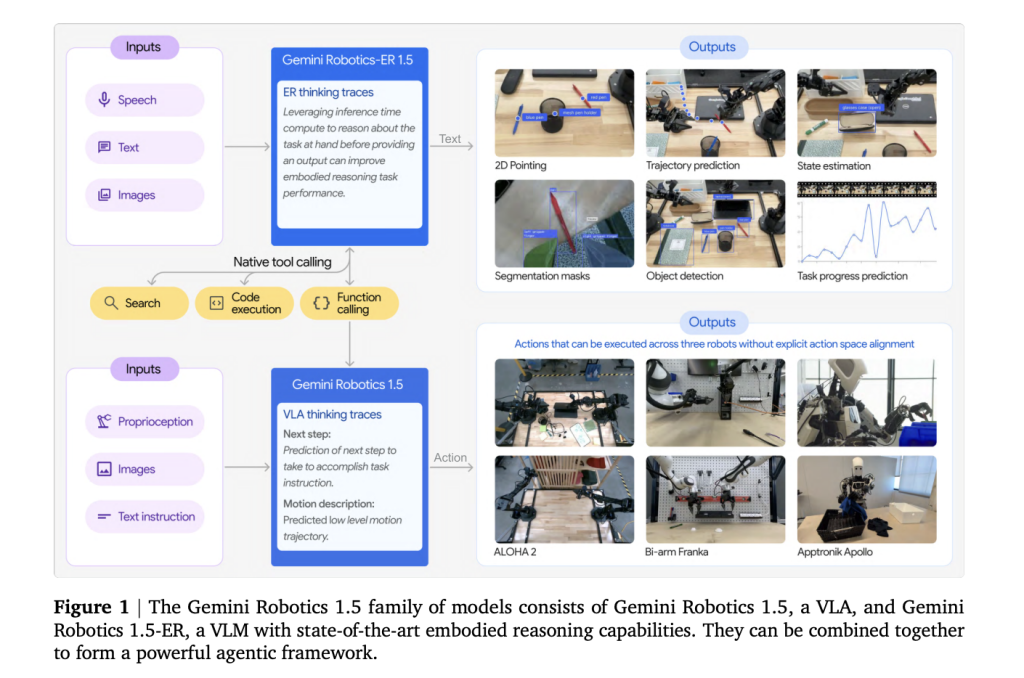
- Gemini Robotics-er 1.5 (Inference/Organization): A multimodal planner, ingesting images/video (and optional audio), ground reference via 2D points, tracks progress and calls external tools (e.g., web search or local API) to get constraints, and then issues sub-targets. Can be passed Gemini API Learn from Google.
- Gemini Robot Technology 1.5 (VLA controller): A visual language action model converts instructions and perception into motor commands, resulting in clear traces of “thinking” to break long tasks down into short-distance skills. During initial launch, availability is limited to selected partners.
Why separate cognition from control?
Earlier end-to-end VLA (Visual Language Action) effort planning, validating success and crossing across implementation plans. Gemini Robot 1.5 isolates these problems: Gemini Robot handle Deliberation (Scenario reasoning, sub-targeting, successful detection), and VLA specializes in research implement (Close-loop visual motion control). This modularity improves interpretability (visible internal traces), error recovery and long horse reliability.
Movement transfer across implementations
The core contribution is Motion Transfer (MT): Training VLA based on a unified motion representation constructed from heterogeneous robot data –Aloha,,,,, Frank with both armsand Apptronik Apollo– Thus, skills learned on one platform can be transferred to another platform by zero shooting. This reduces the collection of robot data every time and reduces the gaps in SIM to space by reusing the cross-seat priors.
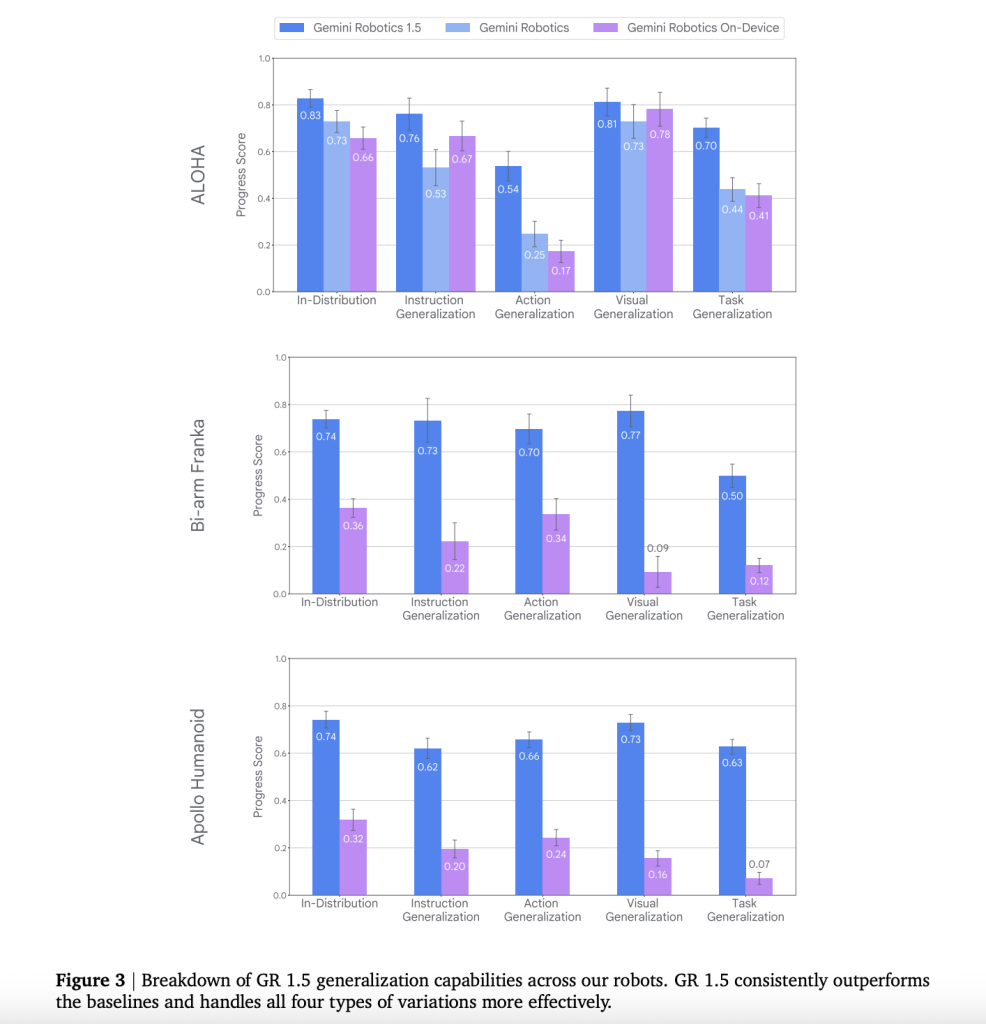
Quantitative signal
The research team demonstrated control A/B comparisons for real hardware and aligned Mujoko scenarios. This includes:
- Summary: Robotics 1.5 surpasses the previous Gemini Robot baseline in the following description, on three platforms, action generalization, visual generalization, and task generalization.
- Zero Shooting Cross Robot Skills: MT generates measurable benefits progress and success When transferring skills to cross-implementation programs (e.g. Franka→Aloha, Aloha→Apollo), not just to improve part of the progress.
- “Thinking” improves acting: Enabling VLA believes that traces will increase the completion of long-distance tasks and stabilize mid-term plan revisions.
- End-to-end proxy income: pair Gemini Robot Compared to VLA agents, VLA agents can greatly improve the progress of multi-step tasks (e.g., desk organization, cooking sequences), while baseline orchestration based on Gemini-2.5-Flash.
Safety and assessment
The DeepMind Research team highlights hierarchical controls: policy adjustment dialogue/planning, security awareness grounding (e.g., not pointing to dangerous objects), low-level physical limitations and an extended evaluation suite (e.g., Asimov/Asimov style scene testing and automatic red team to cause edge case failure). The goal is to capture the burden of hallucinations or non-existent objects before driving.
Competitive/Industry Environment
Gemini Robot 1.5 is transforming from “single guidance” robot technology to actingwith clear multi-step autonomy for web/tool use and cross-platform learning, a feature set related to consumer and industrial robotics. Early partner visits center on established robotics vendors and humanoid platforms.
Key Points
- Two-model architecture (ER↔vla): Gemini Robotics-ER 1.5 Reasoning reflected by handles – space grounding, planning, success/progress estimation, tool call – Robotics 1.5 It is the visual language executor who issues motor commands.
- “Before thinking” control: VLA will produce clear intermediate reasoning/traces during execution, improving long horse decomposition and adaptation to mid-tasks.
- Movement transfer across implementations: A single VLA checkpoint repeats the skills of heterogeneous robots (Aloha, Bi-Arm Franka, Apptronik Apollo), making zero-/small shots perform across robots rather than retraining each platform.
- Tool adjustment plan: ER 1.5 can call external tools (e.g., web search) to get constraints and then conditional planning after checking local weather or applying recycling rules for a specific city – eg, packaging.
- Quantitative improvements to previous baselines: This technical report records higher command/action/visual/task overviews and better progress/success on actual hardware and alignment simulators; the results cover both transit and long horse tasks.
- Availability and access: It’s 1.5 Available Gemini API (Google AI Studio) with documentation, examples and preview knobs; Robotics 1.5 (VLA) is limited to the selection partners on the public waitlist.
- Safety and Assessment Position: DeepMind highlights layered safeguards (with policy adjustment plans, safety awareness grounding, physical restrictions) and Upgraded Asimov Benchmarks and adversarial assessments to detect the burden of risk behavior and hallucinations.
Summary
Gemini Robot 1.5 Operation Cleaning Separation Reflected reasoning and control,Add to Movement transfer Recycle data across robots and show developers the inference surface (point grounding, progress/success estimation, tool calls) through the Gemini API. For teams that build real-world agents, the design eases the data burden per platform and enhances long-distance reliability – while keeping security within dedicated test kits and guardrails.
Check Paper and Technical details. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥 (Recommended Reading) NVIDIA AI Open Source VIPE (Video Pose Engine): a powerful and universal 3D video annotation tool for spatial AI