
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031

Ghostbuster’s structure, which is our new latest method for detecting AI-generated text.
Large language models like Chatgpt are written in a good way – in fact, they have become a problem. Students have started using these models for proxy assignments, resulting in some schools banning Chatgpt. Additionally, these models are prone to text with factual errors, so alert readers may wonder if the generated AI tools have been used to include news articles or other source codes before trusting.
What can teachers and consumers do? Existing tools for detecting AI-generated texts sometimes have poor effects on data that are different from those trained. Furthermore, if these models mistakenly classify real human writing as AI-generated, they could endanger students whose real work is questioned.
Our recent paper introduces Ghostbuster, the latest method for detecting AI-generated text. Ghostbuster works by finding the probability of generating each token in the document under several weaker language models, and then combining functions according to these probability as input to the final classifier. Ghostbuster does not need to know which model to use to generate the document, nor does it need the possibility of generating the document under that particular model. This property makes Ghostbuster particularly useful for detecting text that may be generated by unknown models or black box models, such as popular business models Chatgpt and Claude, for which these probabilities are not available. We are particularly interested in ensuring that Ghostbuster is well generalized, so we evaluate across a variety of ways in which text can be generated, including different domains (using newly collected papers, news and story datasets), language models, or cues.

Examples of human and AI-generated text from our dataset.
Why this method?
Many current AI-generated text detection systems fragilely classify different types of text (e.g., different writing styles or different text generation models or hints). Using confusing simple models alone often fails to capture more complex features and does a particularly poor job of new writing domains. In fact, we found that only confusion baselines are less likely than randomness in certain areas (including data on non-native English speakers). Meanwhile, classifiers based on large language models such as Roberta can easily capture complex features, but are too high for training data and generalize badly: We find that Roberta baseline has catastrophic worst generalization performance, sometimes even worse than just one baseline. By calculating the probability of text generated by a particular model, the zero-shooting method that classifies text without training on the labeled data is also often poorly when actually generating text using different models.
How Ghostbuster works
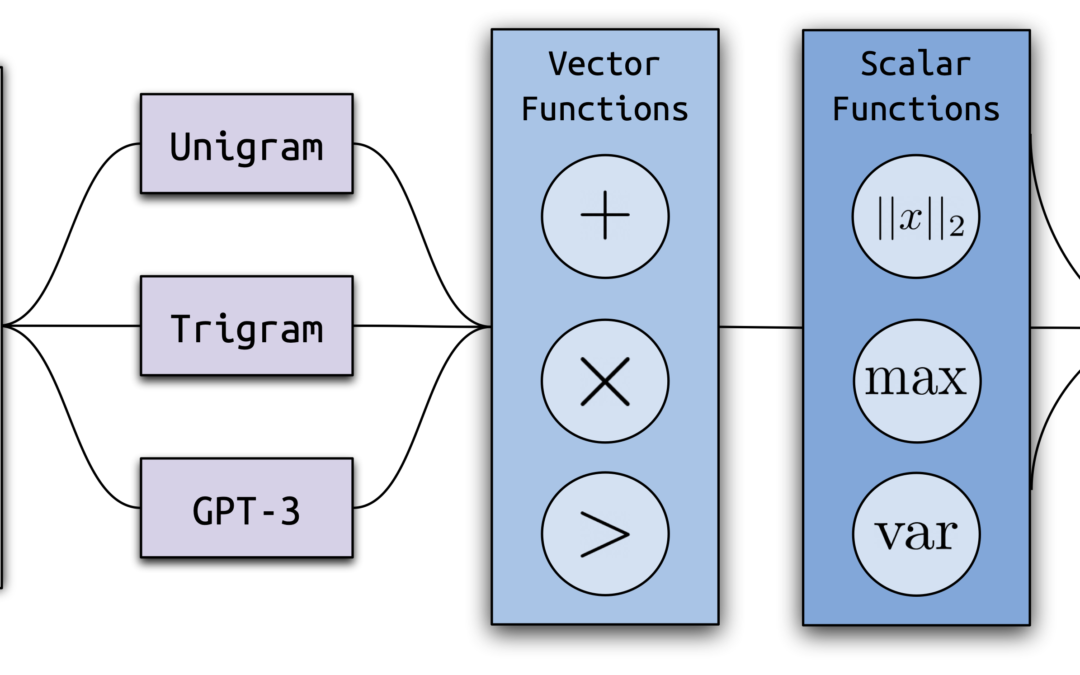
Ghostbuster uses three-stage training process: calculating probability, selecting functions and classifier training.
Calculate probability: We convert each document into a series of vectors by computing the probability of a series of weaker language models (one Umigram model, a Trigram model and two non-guided GPT-3 models ADA and DAVINCI).
Select function: We use a structured search process to select features that are (1) defining a set of vector and scalar operations that combine probabilities, and (2) using the forward function to select a useful combination of these operations and repeatedly adding the best remaining functions.
Classifier training: We trained a linear classifier that introduces the best probability function and some other manual selection functions.
result
When training and testing the same domain, Ghostbuster reached 99.0 F1 in all three datasets, with a margin of 5.9 F1 better than GPTZERO and detected with 41.6 F1. In the domain, Ghostbuster averaged 97.0 F1 under all conditions, performing better than 39.6 F1, while GPTZERO’s detection was 7.5 F1. When we evaluated the intradomain on all datasets, our Roberta baseline reached 98.1 F1, but its generalization performance was inconsistent. Apart from creative writing, Ghostbuster outperformed Roberta’s baseline, except for the non-domain, and fared much better than Roberta’s (13.8 f1 Margin).
The result is the inner and outer domain performance of Ghostbuster.
To ensure that Ghostbuster is robust to multiple ways users may drive models (such as requesting different writing styles or reading levels), we evaluated the robustness of Ghostbuster to several timely variants. Ghostbuster outperformed all other test methods for these hint variants, using 99.5 F1. To test the generalization across models, we evaluated the performance of Claude-generated texts, where Ghostbuster also outperformed all other test methods in a 92.2 F1 way.
The AI-generated text detector is fooled by gently editing the generated text. We examined the robustness of Ghostbuster for editing, such as interchanging sentences or paragraphs, reordering characters, or replacing words with synonyms. Most changes at the sentence or paragraph level do not significantly affect performance, although performance will be smoothly degraded if the text is edited by repeated interpretations, using commercial detection of evaders (such as undetectable AI), or making a large number of word or character level changes. Performance is also the best in longer documentation.
Since AI-generated text detectors may mistake texts from non-native speakers for AI-generated, we evaluated Ghostbuster’s performance in writing of non-native English speakers. All tested models have over 95% accuracy in two of the three test datasets, but have poorer accuracy in the third set of short papers. However, document length may be the main factor here, as Ghostbuster performs as well on these documents (74.7 F1) as other extraterritorial documents of similar lengths (75.6 to 93.1 F1).
Users who want to apply Ghostbuster to potentially limit text usage in the real world (e.g., student papers written by ChatGpt) should note that the wrong text is more likely to be shorter text, away from the domain names of trained domains (e.g., different breeds of English), and models written by English, humans to build a model, or a model, or an inspirational, or a model. To avoid permanent algorithmic hazards, we strongly recommend that so-called text power generation be automatically punished without human supervision. Instead, if classifying someone’s writings as AI-generated people might hurt them, we recommend using caution, human use. Ghostbuster can also help with a variety of lower risk applications, including filtering AI-generated text from language model training data and checking whether online information sources are AI-generated.
in conclusion
Ghostbuster is a state-of-the-art AI-generated text detection model with 99.0 F1 performance in tested domains, representing substantial progress in existing models. It generalizes well to different domains, hints, and models and is great for identifying text from black boxes or unknown models, as it does not require access to probabilities from the specific model used to generate the document.
Ghostbuster’s future direction includes providing an explanation for model decisions and improving the robustness of attacks specifically deceiving detectors. AI-generated text detection methods can also be used with alternatives such as watermarks. We also hope that Ghostbuster can help in a variety of applications, such as filtering language model training data or tagging AI-generated content on the web.
Try Ghostbuster here: Ghostbuster.App
Learn more about Ghostbuster here: (paper) (code)
Try to guess here whether the text is generated by ai: