
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
Alibaba’s QWEN team has just released two new QWEN3-NEXT-80B-A3B models of FP8 quantization checkpoints, which are two post-training variants –instruct and thinking– Extra long background and MOE efficiency under high throughput recommendations. The FP8 repository reflects the release of BF16, but packages the “fine-grained FP8” weight (block size 128) and deployment instructions for SGLANG and VLLM Nightly Builds. The benchmark in the card is the benchmark of the original BF16 model; for convenience and performance, FP8 is provided, which is not a separate evaluation run.
What’s in the A3B stack
The QWEN3-NEXT-80B-A3B is a hybrid architecture that combines gated Deltanet (linear/AC style attention substitution) and gated attention, intertwined with ultra-high Experts (MOE). The 80B total parameter budget activates approximately 3B parameters through 512 experts (10 routes + 1 share). The layout is specified as 48 layers arranged into 12 blocks: 3×(Gated DeltaNet → MoE) followed by 1×(Gated Attention → MoE). The native context is 262,144 tokens, up to ~1,010,000 tokens were verified using rope scaling (yarn). The hidden size is 2048; note that 16 Q heads and 2 kV heads 256; Deltanet uses 32 V and 16 QK linear heads on the head of DIM 128.
The QWEN team reported that on downstream tasks, the 80B-A3B base model outperformed QWEN3-32B at ~10% of its training cost and was driven into the 32K context by low activation in MOE and multi-token token Prediction (MTP). Indicates that the variant is correct (No
FP8 release: actual changes
The FP8 model card indicates that it is quantized as “fine-grained FP8” and has a block size of 128. The deployment is slightly different from BF16: SGLANG and VLLM both require the current main/night build and provide sample commands and optional MTP for the 256K context. Thinking FP8 card also recommends inference parser logos (e.g. --reasoning-parser deepseek-r1 In sglang, deepseek_r1 in vllm). These releases are subject to the Apache-2.0 license.
Benchmark (report BF16 weight)
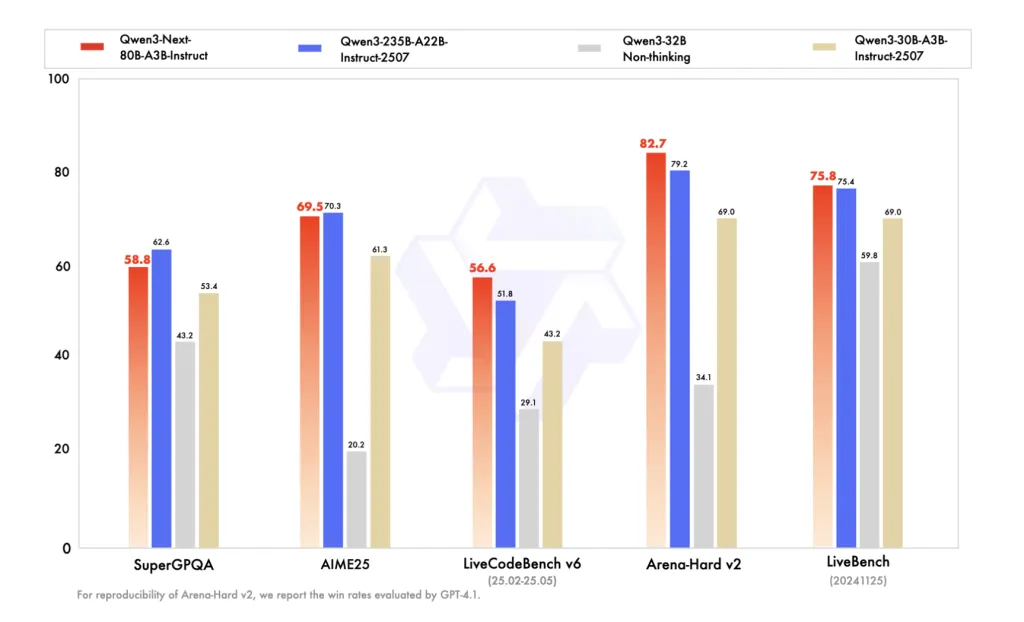
Instructing the FP8 card to reproduce the BF16 comparison table of QWEN, QWEN3-NEXT-80B-A3B-ISSCRUCT and QWEN3-235B-A222B-INSTRUCT-2507 are the same as several knowledge/inference/coding benchmarks, and at long-distance workloads (up to 256K). The Thinking FP8 card lists AIME’25, HMMT’25, MMLU-Pro/Redux, and LiveCodeBench v6, where Qwen3-Next-80B-A3B-Thinging surpasses earlier Qwen3 Thinking releases (30B A3B-2507, 32B) and claims wins over Gemini-2.5-Flash-Thinging on multiple benchmarks.
Training and post-training signals
The series is trained on ~15t tokens before training. QWEN highlights the increase in stability (zero center, weight-determined layer specification, etc.) and uses GSPO for thinking models in post-RL training to handle the mixed attention + high appearance MOE combination. MTP is used to speed up reasoning and improve training training signals.
Why is FP8 important?
On modern accelerators, FP8 activation/weighting reduces memory bandwidth pressure and resident footprint compared to BF16, thus allowing larger batch sizes or longer sequences at similar delays. Since A3B only routes ~3B parameters per token, in the long post scheme, a combination of FP8 + MOE sparse compound compound throughput gains is especially when paired by MTP to exposed in the service flag. That is, quantification interacts with routing and attention variants. The real-world acceptance rate of speculative decoding and end-task accuracy may vary with engine and kernel implementation, so Qwen uses current SGLANG/VLLM and guides to adjust speculative settings.
Summary
QWEN’s FP8 release makes the 80b/3b-Active A3B stack practical to be used in the 256K context of mainstream engines, thus retaining a high-throughput path to hybrid MOE design and MTP. This model card can be kept benchmark from BF16, so the team should verify the accuracy and latency of FP8 on their own stack, especially with inference parsers and speculative settings. Net results: Lower memory bandwidth and improved concurrency, no architectural regression, positioned as long text production workloads.
Check QWEN3-NEXT-80B-A3B model in two post-training variants –instruct and thinking. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please feel free to follow us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥 (Recommended Reading) NVIDIA AI Open Source VIPE (Video Pose Engine): a powerful and universal 3D video annotation tool for spatial AI