
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
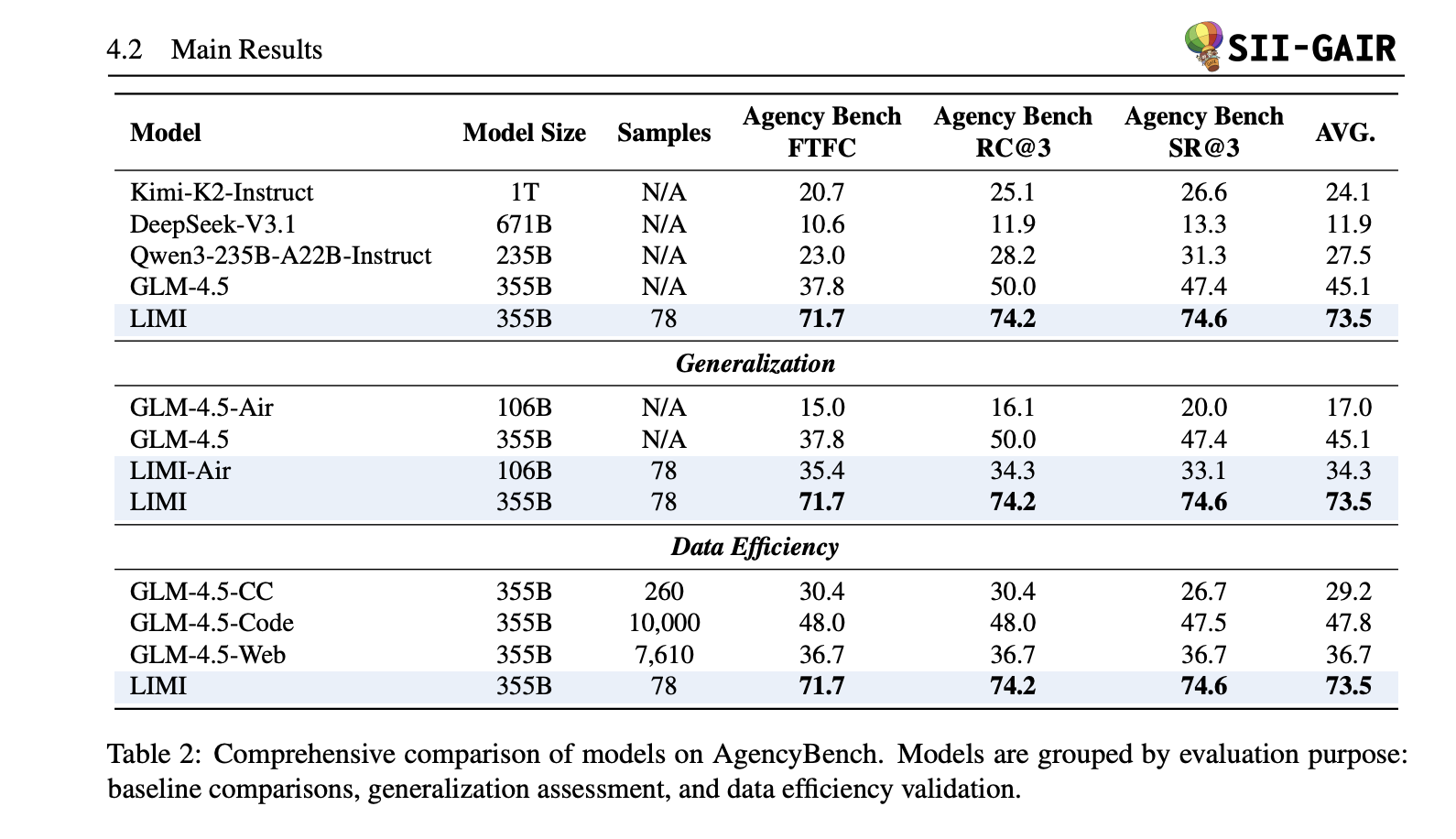
Do curated tool-based demonstrations build more powerful software agents than large amounts of general guidance data? A group of researchers from Shanghai Ruotan University and SII Generative AI Research Laboratory (GAIR) propose Limi (“Less and more for agency”)a supervised fine-tuning approach that turns base models into powerful software/research agents 78 sample. Limi score 73.5% average opening agent (FTFC 71.7, RC@3 74.2, SR@3 74.6), beat the strong baselines (GLM-4.5 45.1, QWEN3-235B-A222B 27.5, KIMI-K2 24.1, DeepSeek-V3.1 11.9), and even surpassed the trained variants 10,000 Sample –Use 128× less data.

what’s new?
- agency efficiency principle:limi pointed out agency capability Scale with more Data quality/structure than the original sample count. Research team fine-tunes GLM-4.5/glm-4.5-air on 78 Changma, tool usage traces (samples) and reported huge gains for agency and generalization suites (TAU2-BENCH, evalplus-He/MBPP, DS-1000, SCICODE).
- Minimal but intensive supervision. Each trajectory (~13k – 152k tokens; ~42.4k avg.) captures the complete multi-turn workflow – model inference, tool calls and environment observations – in sii-cli execution environment. task spanningambience coding” (interactive software development) and Research workflow (search, analysis, experimental design).
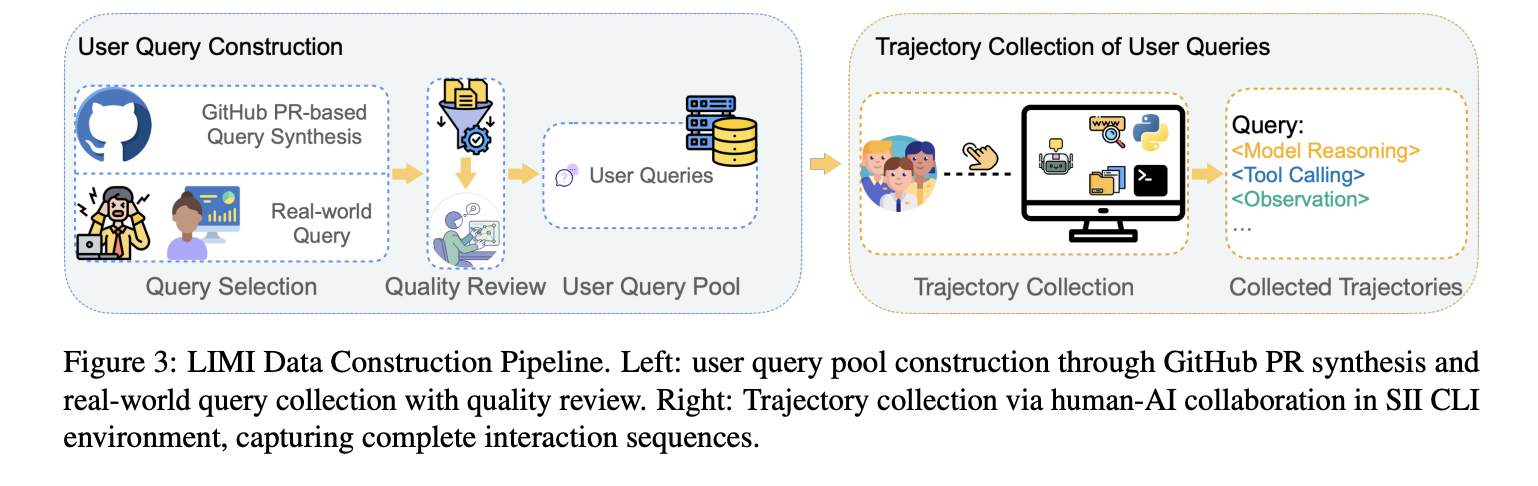
How does it work?
- Basic model: GLM-4.5 (355b) and GLM-4.5-Air (106b). training use slime The SFT framework has the same configuration in comparisons (to isolate data effects).
- Data construction: 60 real-world queries from practitioners + 18 synthesized from high-impact GitHub PRs (intensive QA by PhD annotators). For each query, Limi logs the full agent trace to successfully complete the internal sii-cli.
- Evaluate: agent (r = 3 rounds) with ftfc, sr@3, rc@3; plus generalization kit (TAU2-AIRLINE/RETAIL PASS^4, EDARPLUS HE/MBPP, DS-1000, SCICODE).
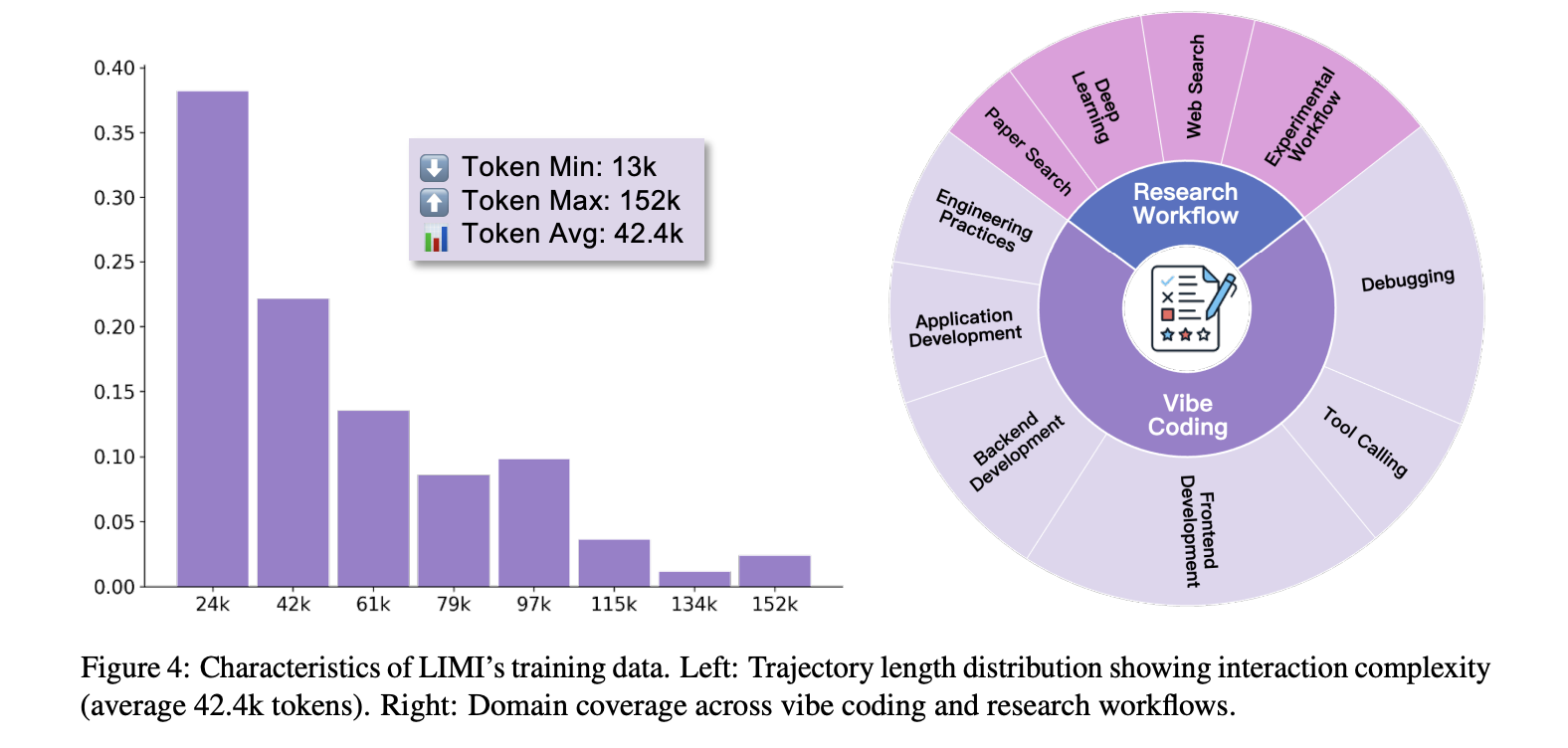
result
- Agency (AVG): 73.5%. Limi vs.GLM-4.5 (+28.4 points); FTFC 71.7% vs 37.8%;SR@3 74.6% vs 47.4%.
- Data efficiency: limi(78 sample) outperforms the trained GLM-4.5 AFM encoded SFT (10,000 samples): 73.5% vs 47.8%–+53.7% absolutely with 128× Less data. A similar gap also accommodates AFM-Webagent (7,610) and CC Bench-traj (260).
- Summary: Across tool usage/coding/scientific computing, Limi averaging ~57%over GLM-4.5 and other baselines; without tool access, Limi still boots slightly (50.0% vs 48.7% for GLM-4.5), indicating intrinsic gain beyond the environment tool.
Key takeaways
- Data efficiency rules scale. Limi arrives 73.5% average usage of agents planned trajectoryexceeds GLM-4.5 (45.1%) and shows +53.7 points Advantages over a 10K samples SFT baseline –128× less sample.
- Track quality, not bulk. The training data is Long horse, tools fixed Workflows in collaborative software development and scientific research, via sii-cli The execution stack referenced by the file.
- Gains on Earth. Leamy Report FTFC 71.7%,,,, SR@3 74.6%,strong RC@3detailed table showing larger margins over baseline; summary suite (Tau2, evalplus-He/MBPP, DS-1000, SCICODE) average 57.2%.
- Work across scales. fine-tuning GLM-4.5 (355b) and GLM-4.5-air (106b) Both produced large deltas at their base, indicating the robustness of the method to model size.
The research team trained the GLM-4.5 variant on 78 curated, long-horse trajectories captured in a CLI environment, covering software engineering and research tasks. It reported an agency average of 73.5% for FTFC, RC@3 and SR@3 metrics; the baseline GLM-4.5 reported 45.1%. Comparison to the SFT baseline of 10,000 AFM codes shows 73.5% vs 47.8%; tool-free assessment indicates intrinsic growth (LIMI vs 48.7% GLM-4.5). The track is multi-curved and token-intensive, emphasizing planning, tool orchestration, and validation.
Check Paper,,,, Github page and Model card on HF. Feel free to check out our Github page for tutorials, code and notebooks. Also, please feel free to follow us twitter And don’t forget to join our 100K+ ml subreddit and subscribe our newsletter.
Asif Razzaq is the CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence for social good. His most recent endeavor is the launch of the AI media platform Marktechpost, which provides in-depth coverage of machine learning and deep learning news that both sounds technical and understandable to a broad audience. The platform has over 2 million views per month, illustrating its popularity among its audience.
🙌 Follow Marktechpost: Add us as your go-to source on Google.