
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
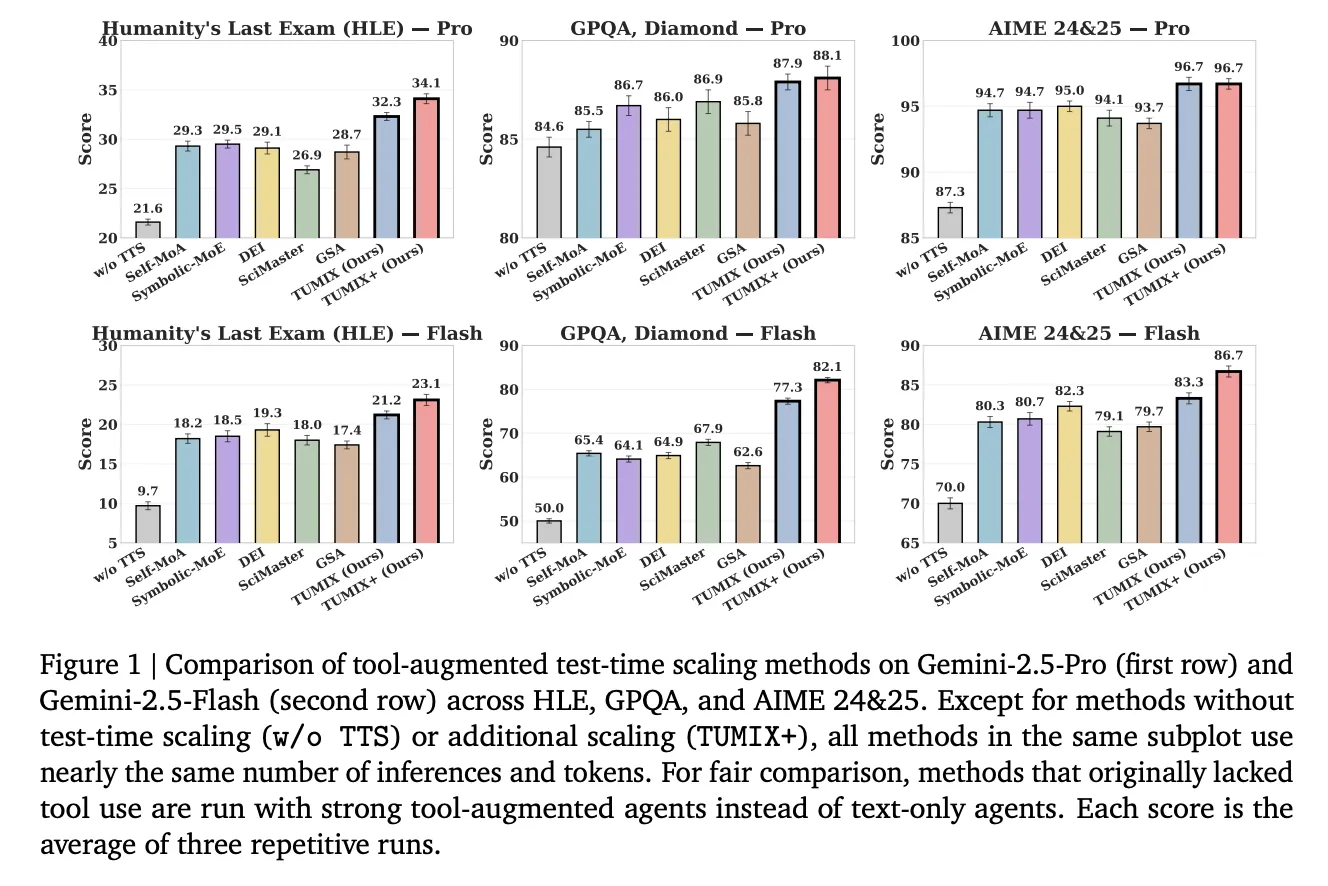
What if you could resample the Gemini-2.5 Pro by mixing 12-15 tooled proxy, instead you could push the Gemini-2.5 Pro to 34.1% of HLE and stop early? Along with collaborators at MIT, Harvard University and Google DeepMind, introduces Google Cloud AI research tumix (tool uses mixture)– A test timeframe that combines heterogeneous proxy styles (text, code, search, bootstrap variants only) and let them Share the intermediate answers in a few refinementsThen Stop early By LLM-based judges. Results: Low cost accuracy in hard inference benchmarks this,,,,, GPQA-Diamondand Aime (2024/2025).
So, what is different?
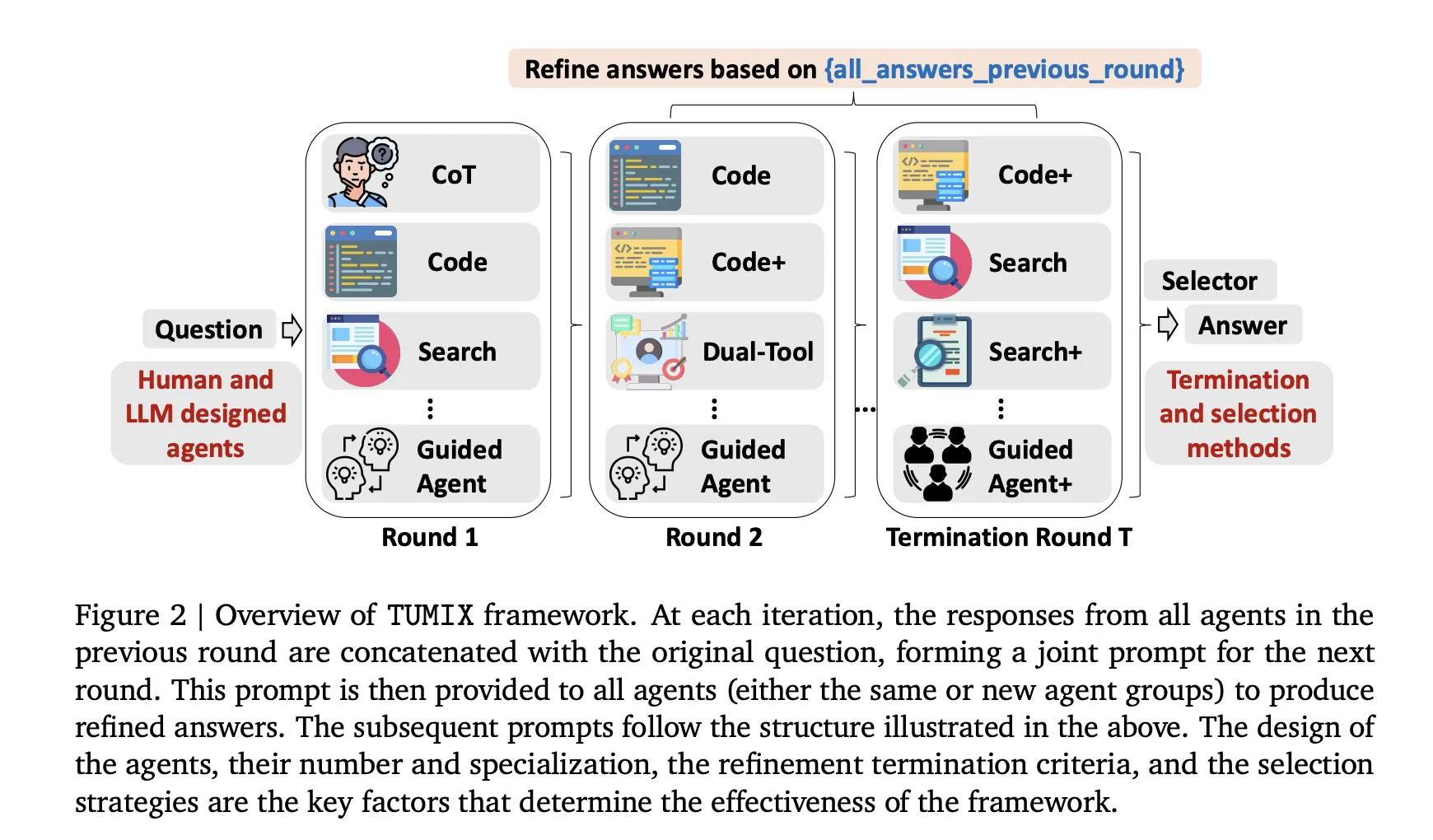
- Mixed method, not just more samples:Tumix runs ~15 proxy styles Crossing chain of ideas (COT), code execution, web search, dual tool proxy and bootstrap variants. Each round, each agent sees (a) the original question, and (b) the previous answers from other agents, and then comes up with a refined answer. this Message Communication The average accuracy was improved earlier, while diversity gradually collapsed, thus stopping the problem.
- Adaptive early termination: one LLM-AS-Gudge Once the answer shows strong consensus (lowest circular threshold). This preserves accuracy About 49% of the inference cost with fixed wheel modification; since late rounds are symbolic, the token cost drops to about 46%.
- Automatically designed agent: Going beyond artificially made agents, Tumix prompts basic LLM Generate a new proxy type;Mix these with manual combination to produce Extra ~++1.2% Average lifts without additional costs. The “dessert” of experience is ~12–15 proxy style.
How does it work?
Tumix runs a set of heterogeneous agents in parallel – text chains only, code execution, web search and guided variants, then iterates over a small number of refinement bombs, each agent has the conditions for the original question on the original question, as well as other agents and other previous rulers and answers (structural comments – distribution). After each round, a judge based on LLM evaluates consensus/consistency to decide Terminate early;If confidence is insufficient, another round will be triggered, otherwise the system will be completed by simple aggregation (e.g., majority votes or selectors). This mixed-use tool design deals with brute force resampling Various reasoning pathsIncrease the coverage of the correct candidates when controlling the token/tool budget; empirically, benefits are saturated around 12-15 proxy styles, stopping early preservation of diversity, and reducing costs without sacrificing accuracy
Let’s discuss the results
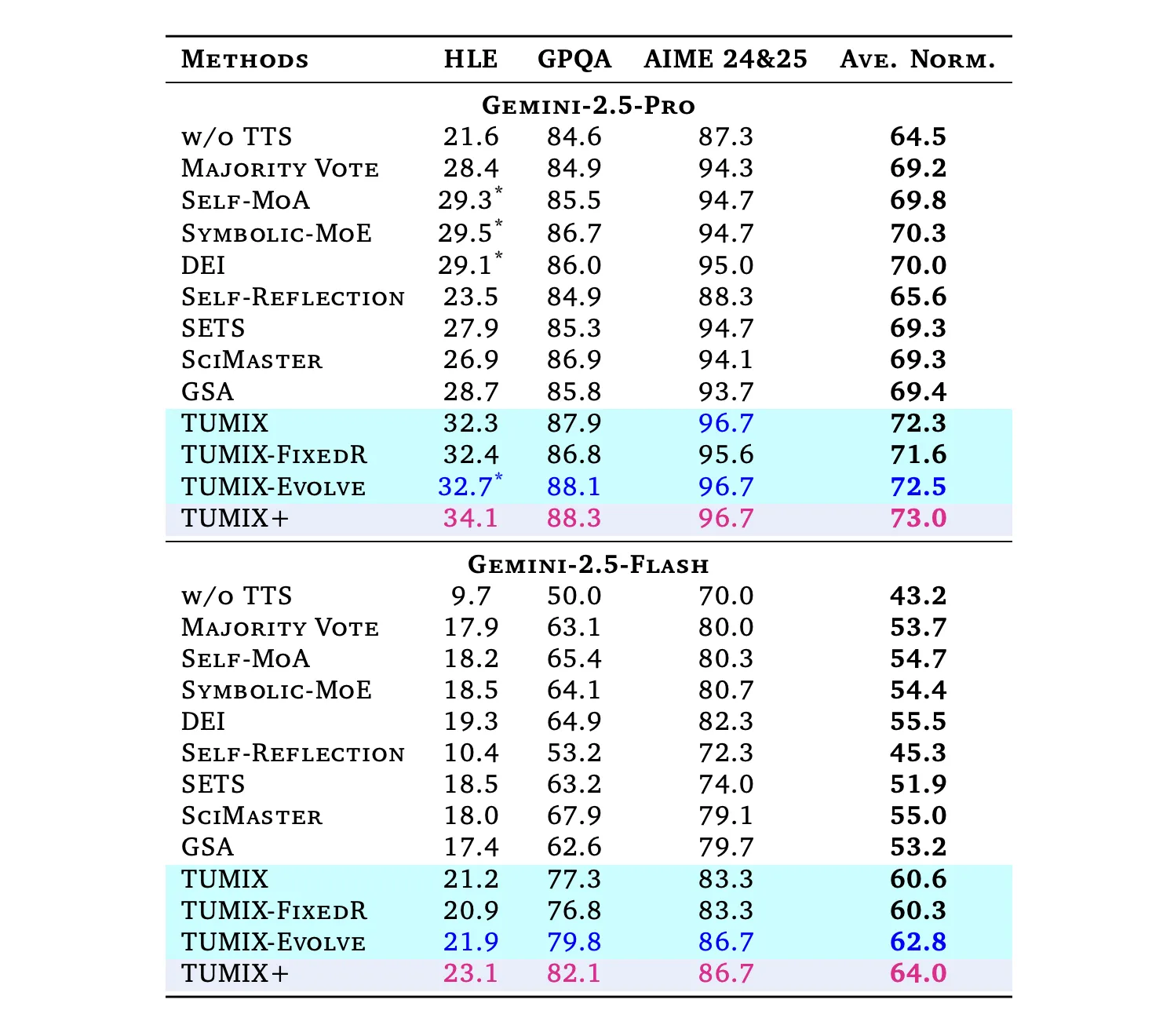
Under comparable inference budgets with powerful tools to enhance baseline tumix produce Best average accuracy;Scaling variant (tumix+) Further push with more calculations:
🚨 (recommended reading) Vipe (video posture engine): a powerful 3D video annotation tool for space AI
- HLE (The Last Exam for Humanity): Pro: 21.6% → 34.1% (Tumix+); flash: 9.7% → 23.1%.
(HLE is a 2500 question, difficulty, multi-domain benchmark is completed in 2025.) - GPQA-Diamond: Pro: Most 88.3%; Flash: the most 82.1%. (GPQA-Diamond is the hardest subset of 198 questions written by domain experts.)
- Aime 2024/25: Pro: 96.7%;flash: 86.7% When testing with Tumix (+).
Cross-task, Tumix average is +3.55% higher than the best previous tool to adjust the test time scaling baseline at a similar costand +7.8% / +17.4% More than Pro/Flash respectively.
Tumix is a great way for Google because it uses test time scaling as a search question rather than a heterogeneous tool strategy rather than brute force sampling. Parallel committees (text, code, search) improve candidate coverage, while LLM-Gudge allows early work to use diversity and reduce token/tool spending under delayed budgets. The HLE rise (with 34.1% of the Gemini-2.5 Pro) is consistent with the 2,500 problem design finalized by the benchmark, while the proxy style “best point” of ~12-15 means that the choice is selected (not generated), which is a limiting factor.
Check Paper. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter. wait! Are you on the telegram? Now, you can also join us on Telegram.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🙌Follow Marktechpost: Add us as the preferred source on Google.