
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
Researchers at Cornell and Google introduced a unified regression language model (RLM) that predicts numerical results directly from code strings (overrides GPU kernel latency, program memory usage, and even neural network accuracy and latency) without the capabilities of manual engineering. Using a single text pair number of decoders, the 300m parameter encoder initialized from T5 gemma-judger can achieve strong hierarchical correlations between heterogeneous tasks and languages, which decodes with constraints to numbers.
what’s new?
- Unified code to metal regression: A RLM predicts (i) peak memory for advanced code (python/c/c/c++, etc.), (ii) latency for Triton GPU cores, and (iii) precision and hardware-specific latency from ONNX graphs by reading raw text representations and decoding digital outputs. No functional engineering, graphics encoder or zero-cost proxy is required.
- Specific results: The report’s relevance includes SpearmanP≈0.93 On the application leetcode memory, p≈0.52 For Triton kernel latency, p> 0.5 average value 17 code olefin languagesand Kendall τ≈0.46 In five classic NAS spaces, compete with graph-based predictors.
- Multi-objective decoding: Since the decoder automatically rotates, the model condition later on the early indicators (e.g., accuracy → human-effect latency), thus capturing the realistic trade-off along the Pareto front.
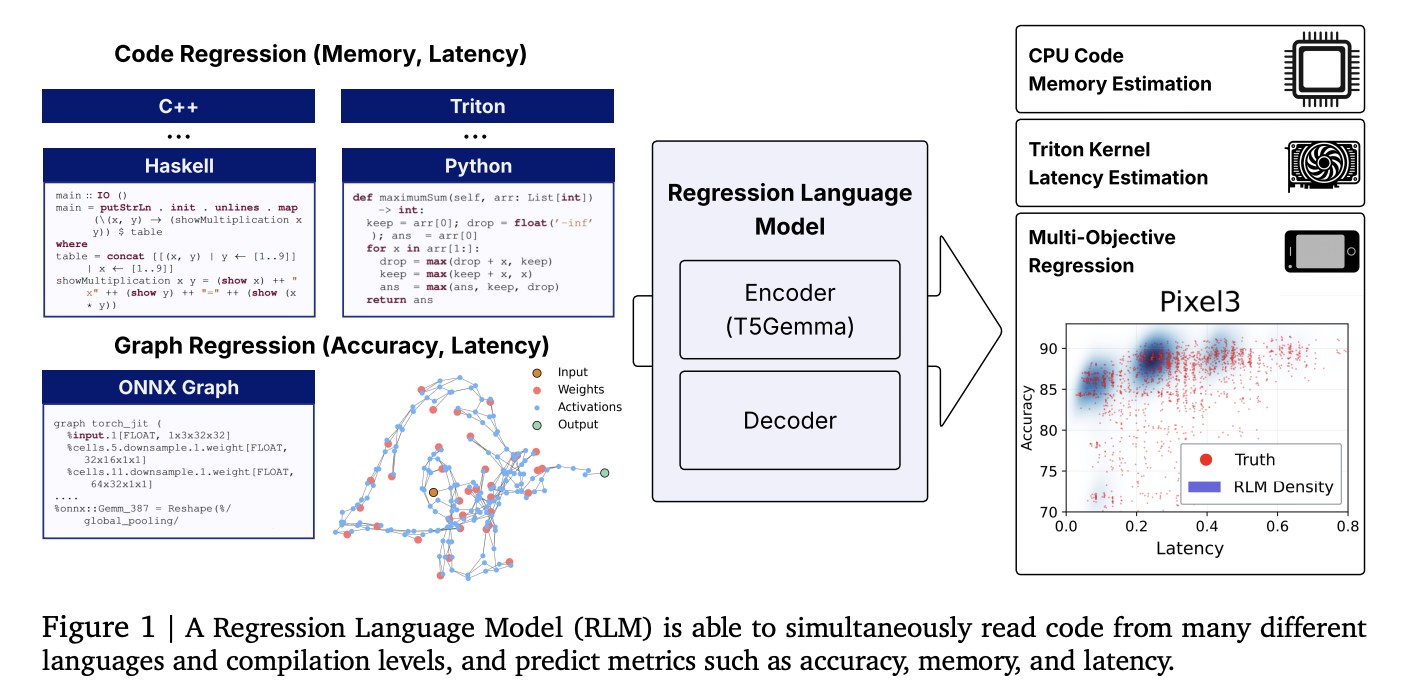
Why is this important?
Compilers, GPU core selection, and performance prediction pipelines in NAS often rely on fragile custom features, syntax trees, or GNN encoders. Think of regression as Next predictions about numbers Standardized stack: Tokenized inputs are plain text (source code, Triton IR, ONNX), and then constrained sampling is used to decode the calibrated numeric string numeric numbers. This reduces maintenance costs and improves transfer of new tasks through fine-tuning.
Data and benchmarks
- Code Regression Dataset (HF): Planning to support Code and Metal Tasks running across applications/LeetCode, Triton kernel latency (kernel book) and Codenet memory footprint.
- NAS/ONNX Kit: NASBENCH-101/201, FBNET architecture, used to be all (MB/PN/RN), Twopath, Hiaml, Inception, NDS and NDS are exported to onnx text Predictive accuracy and device-specific latency.
How does it work?
- backbone:Encoder – decoder with a T5 gemma Encoder initialization (~300m parameter). The input is the original string (code or ONNX). Output digital emissions are Symbol/Exponent/mantissa digital token;Constrained decoding enforces valid numbers and supports uncertainty through sampling.
- Absolute: (i) Read-pre-language accelerates fusion and improves Triton latency prediction; (ii) Digital transmission of decoder only Even if the Y difference is regularized, it will exceed the MSE return. (iii) A dedicated knowledge relationship person who works in ONNX operators will increase the effective environment; (iv) longer contexts are helpful; (v) Scaling to a larger Gemma encoder further improves the correlation with sufficient adjustments.
- Training code. this Return to lm The library provides text-to-text regression utilities, limited decoding, and multitasking preprocessing/fine-tuning recipes.
Important statistics
- Application (Python) memory: Spearman p> 0.9.
- CodEnet (17 languages) memory: Average p> 0.5;The strongest languages include C/C++ (~0.74–0.75).
- Triton kernel (A6000) delay: p≈0.52.
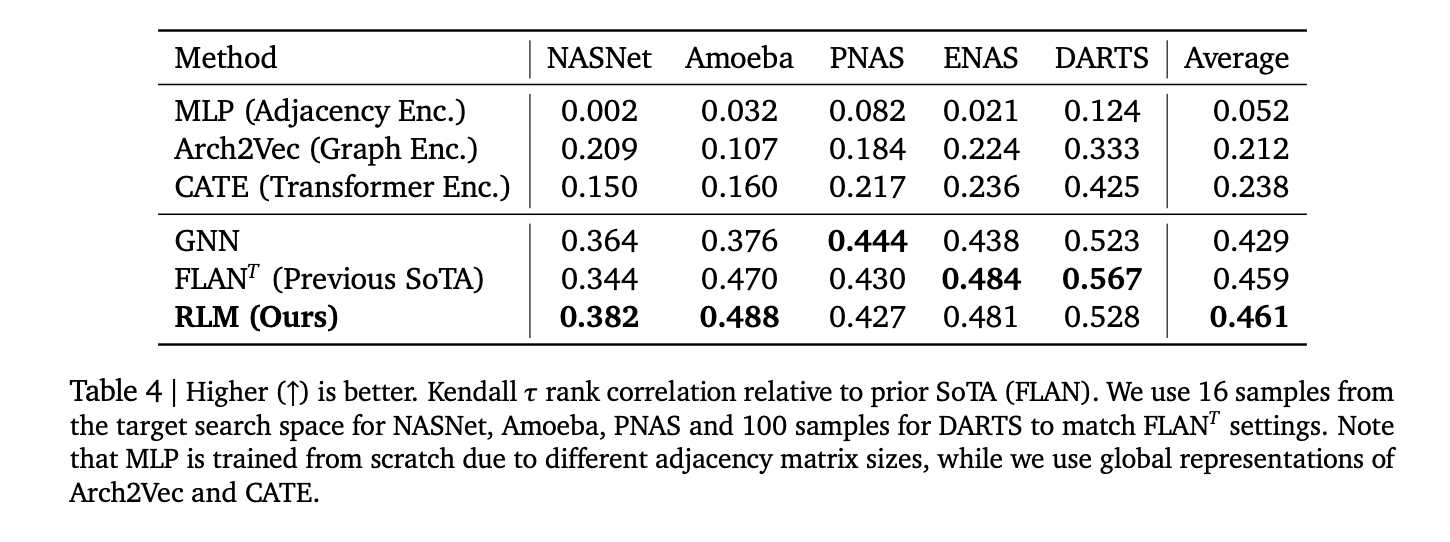
- NAS Ranking: Average Kendall τ≈0.46 Crossing Nasnet, Amoeba, PNA, ENAS, DARTS; competing with Flan and GNN baselines.
Key Points
- Unified code works with metal regression. A ~300m parameter T5GEMMA-INIALIADIAL model (“RLM”) prediction: (a) memory from advanced code, (b) Triton GPU kernel latency, (c) (c) model + model from ONNX + device latency – direct from text, no manual startup features.
- This study shows Spearmanρ>0.9 on application memory, Triton latency has an average of >0.52 in 17 codec languages, and kendall-τ≈0.46 on five NAS spaces.
- The numbers are decoded as text with constraints. Instead of a regression header, RLM emits digital tokens with constrained decoding, thus achieving multi-type, self-rotating outputs (e.g., accuracy, and latency of multi-device) and uncertainty through sampling.
- this Code Regression Dataset Unified Application/LeetCode Memory, Triton Kernel Latency and Codenet Memory; Return to lm The library provides training/decoding stacks.
How this work attributes performance predictions to text-to-digit generation is very interesting: compact T5Gemma-Initialized Algorithmization Algorithmization Algorithmization Algorithmization Algorithmization Algorithmization Algorithmization Algorithmization Algorithmization Algorithmization Read Source (Python/c++), Triton kernel or ONNX graphics and emits calibrated numbers through constraint decoders. Reported correlations – memory (ρ>0.9), Triton latency on RTX A6000 (~0.52) and NAS Kendall-τ≈0.46-strong enough to be strong enough for compiler heuristics, kernel pruning, and multi-objective NAS Triage Triage Triage Triage (without BBESPOKE or GNN). Opened datasets and libraries make replication straightforward and reduce barriers to fine-tuning on new hardware or languages.
🚨 (recommended reading) Vipe (video posture engine): a powerful 3D video annotation tool for space AI
Check Papergithub page and Dataset card. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter. wait! Are you on the telegram? Now, you can also join us on Telegram.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🙌Follow Marktechpost: Add us as the preferred source on Google.