
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031

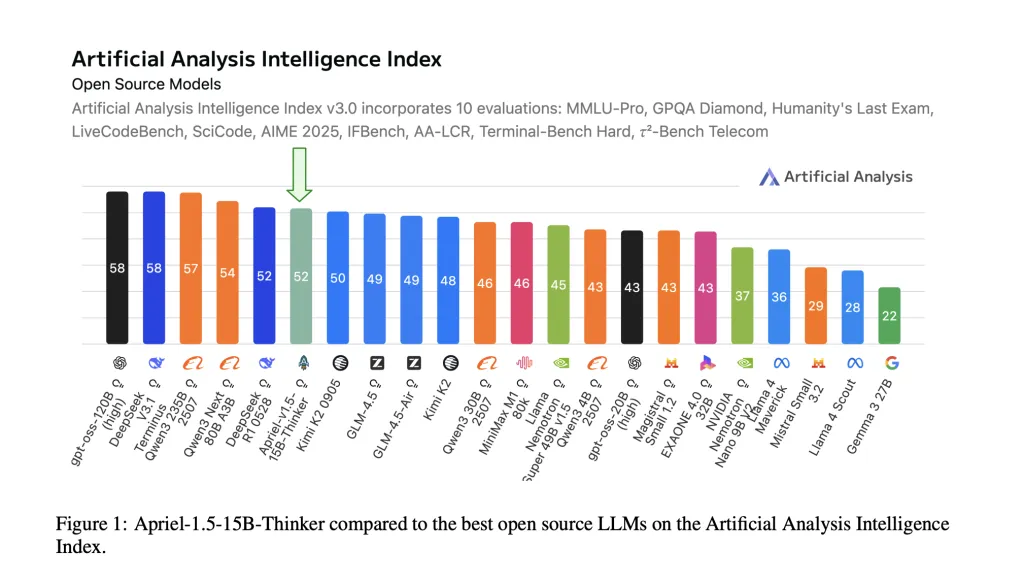
ServiceNow AI Research Laboratory has been released April-1.5-15b-thinkera data-centered training of 15 billion parameter open-volume multi-mode inference model Mid-term training Recipe – Habits to deliberate, then fine-tune –No Reinforcement learning or preference optimization. Compared with SOTA, the model’s artificial analysis intelligence index score is 52, with an 8-fold savings. Checkpoint ships under MIT license while hugging the face.
So, what new features are there for me?
- Boundary-level compound ratings are small. Model Report Artificial Analytical Intelligence Index (AAI) = 52,match DeepSeek-R1-0528 In terms of the merged indicators, it is also large and smaller. AAI summarizes 10 third-party assessments (MMLU-PRO, GPQA Diamond, Human Final Exam, LiveCodeBench, Scicode, Aime 2025, IFBench, IFBench, AA-LCR, AA-LCR, End Basics, Hard, τ²BenchTelecom).
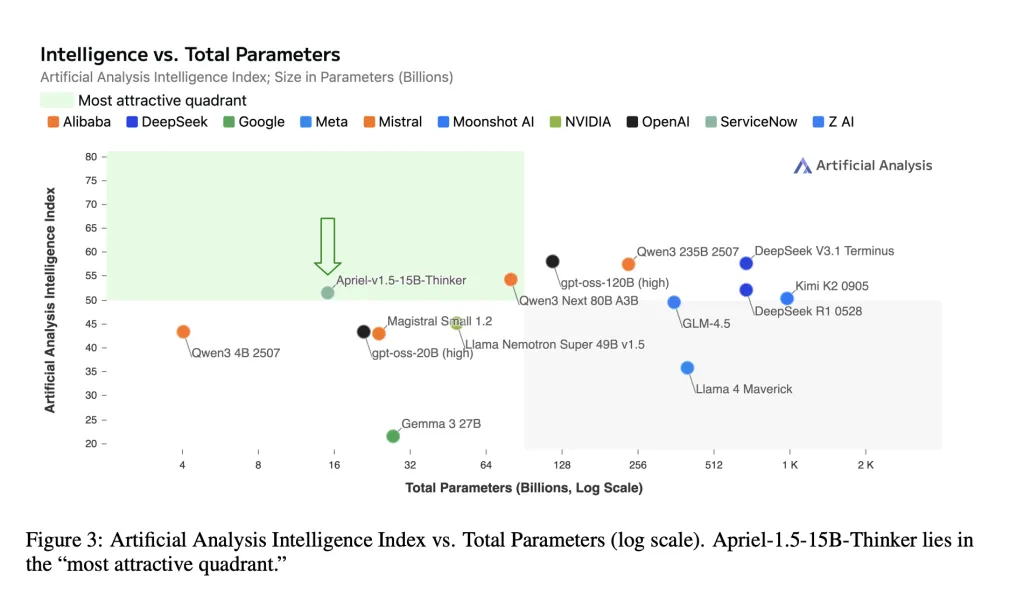
- Deployability of a single GPU. The model card states that the 15B checkpoint is “fitting on a single GPU” for local and pneumatic deployments with fixed memory and latency budgets.
- Open weights and repeatable pipelines. Weights, training formulas and evaluation protocols are publicly available for independent verification.
OK! I understand, but what is the training mechanism?
Basics and upgrades. APRIEL-1.5-15B-INKINCER Start Mistral’s PixTral-12b-Base-2409 Multimode decoder vision stack. Research teams are suitable In-depth upgrade– The decoder layer of 40→48-then Projection network adjustment Keep the visual encoder consistent with the expanded decoder. This avoids preprocessing from scratch when maintaining single GPU deployment.
CPT (continuous preprocessing). Two stages: (1) Mix text + image data to build basic reasoning and document/diagram understanding; (2) Targeted synthetic visual tasks (reconstruction, matching, detection, counting) to sharpen space and compose inference. The sequence lengths extend to 32K and 16K tokens, respectively, and the placement of selective loss on the response token is in the sample in the form of an instruction.
🚨 (recommended reading) Vipe (video posture engine): a powerful 3D video annotation tool for space AI
SFT (Supervised Fine Tuning). High-quality, inference tracking instruction data for math, coding, science, tool usage and instructions; the other two SFT runs (hierarchical subsets; longer letters) are Weight combination Form a final checkpoint. There is no RL (reinforcement learning) or RLAIF (learning from AI feedback).
Data comments. ~25% depth scale text mix From NVIDIA’s nemotron collect.
Oh, wow! Tell me this is the result?
Key text benchmark (by @1/precision).
- Aime 2025 (US Invitational Mathematics Exam 2025): 87.5–88%
- GPQA Diamond (Google Progrood-Poge-Pearts Ammporning, Diamond Split at Graduate Level): ≈71%
- IFBENCH (Instructions follow benchmarks): ~62
- τ² bench (tau square bench) Telecom: ~68
- livecodebench (functional code correctness): ~72.8
use vlmevalkit April competes to score points for repeatability mmmmu/mmu-pro (large number of multidisciplinary multimodal understanding), logicvista, mathvision, mathvista, mathversa, mathverse, mmstar, mmstar, charxiv, ai2d, blinkingwith stronger results on mathematical images that dominate documents/graphs and text.
Let’s summarize everything
APRIEL-1.5-15B-INCHER shows that careful mid-term training (continuous preprocessing + supervised fine-tuning, no reinforcement learning) can be provided 52 on the Artificial Analytical Intelligence Index (AAI) while deploying on a single graphics processing unit. The reported task-level scores (e.g., AIME2025≈88, GPQA diamond ≈71, Ifbench≈62, Tau Fangfang Desktop Telecom ≈68) are consistent with the model card and place 15 billion parameter checkpoints in the most cost-effective band of current open reasoning. For enterprises, this combination (weight, repeatable recipes, and single GPU latency) makes April a practical baseline that can be evaluated before considering a larger enclosed system.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥 (Recommended Reading) NVIDIA AI Open Source VIPE (Video Pose Engine): a powerful and universal 3D video annotation tool for spatial AI