
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
Alibaba released Qwen3-Max, a multi-trillion-parameter expert portfolio (MOE) model that is positioned as the most capable base model to date and is directly publicly disclosed through Qwen Chat and Alibaba Cloud’s Model Studio API. The launch takes Qwen’s 2025 rhythm from preview to production, centering on two variants: Qwen3-Max-Instruct For standard reasoning/coding tasks, qwen3-max thinking A “agent” workflow for tool startup.
New features at the model level?
- Scale and architecture: QWEN3-MAX is designed with MOE (sparse activation for each token) through 100 million parameter marks. Alibaba positioned the model as its largest and most capable date. Public briefings and coverage always describe it as a 1T parameter class system, rather than another mesoscale refresh.
- Training/runtime poses: Qwen3-Max uses sparse Experts design and in ~36T token (~2×Qwen2.5). Corpus bias Multilingual, coding and stemming/inference data. Follow the four-stage formula of QWEN3 after training: long bed cold start → reasoning-focused RL → thinking/thinkless fusion → universal domain RL. Alibaba confirmed > 1T parameters Maximum token count/routing is considered a team report until the official Max Tech report is released.
- Right to use: QWEN chat shows universal UX, while Model Studio openly reasoning and “thinking mode” switching (especially,
incremental_output=trueQWEN3 thinking model requires). Model lists and pricing are located in the model studio with regional availability.
Benchmarks: encoding, proxy control, mathematics
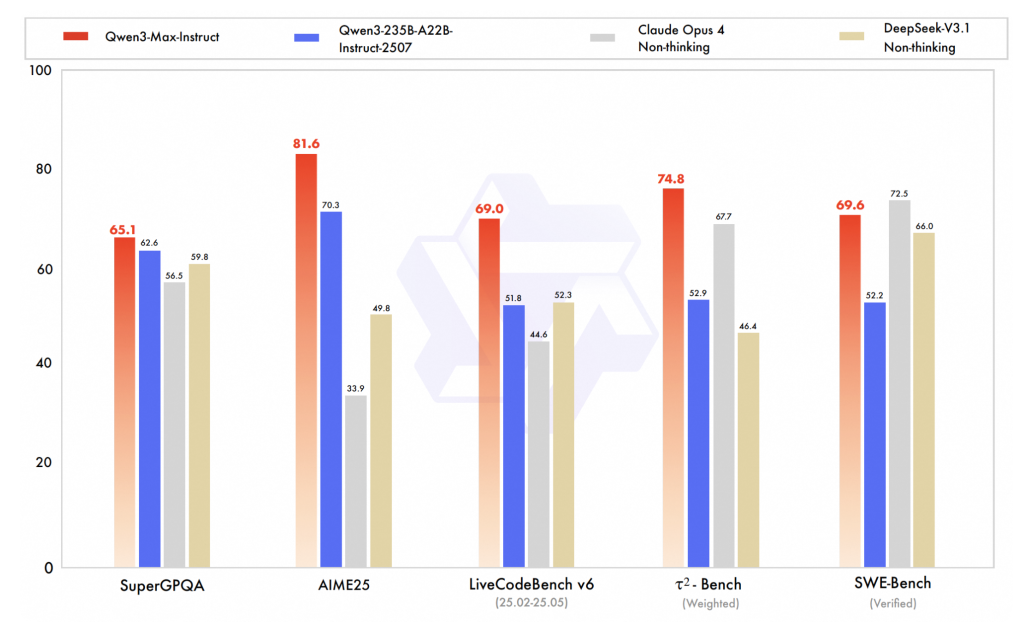
- Encoding (verified SWE basics). According to reports 69.6 Verified on the SWE bench. This puts it above some thoughtless baseline (e.g., DeepSeek v3.1 thoughtless) without thinking in at least one review Claude Opus 4 below. Think of these as points in time; SWE basic evaluation moves rapidly as the harness is updated.
- Proxy tool usage (TAU2 basics). QWEN3-MAX Posts 74.8 On the TAU2 benchmark (agent/tool called evaluation), the peer pairs of named peers are matched in the same report. TAU2 aims to test decision making and tool routing, not just text accuracy, so the benefits gained here make sense for workflow automation.
- Mathematics and Advanced Reasoning (AIME25, etc.). this qwen3-max thinking The track (using tool usage and “re-runtime configuration) is described as a close perfection for key math benchmarks (such as AIME25) across multiple secondary sources and earlier preview coverage. Before official technical reports fall, the “100%” claim is considered as supplier-reported or community-repeated rather than peer-reviewed.

Why do you need two tracks – Teaching and Thinking?
instruct Tight delays, regular chat/coding/inference thinking Enables longer deliberation tracks and explicit tool calls (retrieval, code execution, browsing, evaluator) designed to be designed for higher reliability “proxy” use cases. Crucially, Alibaba’s API documentation formalizes the runtime switch: The QWEN3 thinking model only runs with traffic incremental output enabled;The commercial default value is falseso the caller must set it explicitly. If you are launching an instrument tool or similar idea chain, this is a small but corresponding contract details.
How to reason about returns (signal and noise)?
- coding: Score ranges for 60–70 SWE basic validation are often reflected in non-trivial repository-level reasoning and plaque synthesis under evaluation of line harness constraints (e.g., environment settings, flake testing). If your workload changes on the repo scale code, these deltas are more important than single file coded toys.
- acting: Tau2 Bench emphasizes multi-tool planning and action choices. Improvements here often translate into fragile handmade policies in production agents, provided your tool API and execution sandbox are robust.
- Mathematics/Verification: The “nearly perfect” numbers from heavy/thought mode emphasize the value of extended review plus tools (calculators, validators). The portability of these benefits to open tasks depends on your evaluator design and guardrail.
Summary
Qwen3-Max is not a trailer, it is a deployable 1T parameter MOE with recorded mindset semantics and reproducible access paths (Qwen Chat, Model Studio). Make everyday benchmarks a strong direction, but continue to float locally; the hard-to-verify facts are scale bars (≈36T tokens, >1T parameters) and API contracts for tool startup (incremental_output=true). For the team building coding and proxy systems, this is ready for hands-on trials and internal control of the SWE-/TAU2 style suite.
Check Technical details,,,,, API and Qwen Chat. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥 (Recommended Reading) NVIDIA AI Open Source VIPE (Video Pose Engine): a powerful and universal 3D video annotation tool for spatial AI