
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
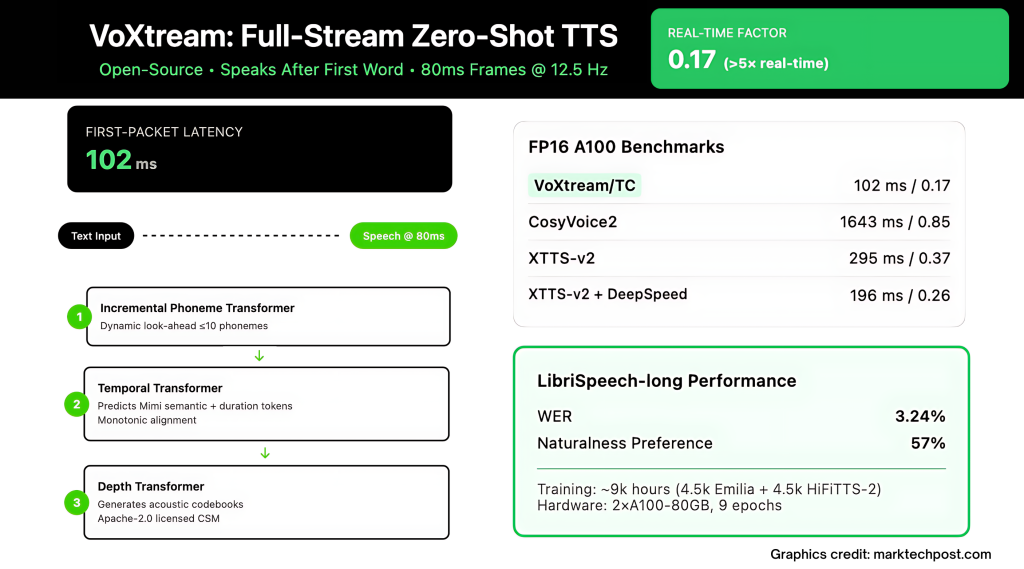
Real-time agents, live dubbing and simultaneous translation were killed in a thousand milliseconds. Most “stream” tts (text-to-speech) stacks are still waiting for a lot of text to make sound, so humans hear the rhythm of silence before the sound begins. Voxtream (released by KTH’s speech, music and listening group) attacks this: It starts speaking After the first wordoutput audio 80ms framesand report 102 MS first packet delay (FPL) On modern GPUs (compiled with Pytorch).
What exactly is “full stream” TTS? How is it different from “output stream”?
The output stream system decodes the speech in the block, but still requires The entire input text Early; the clock starts to arrive late. Full flow System consumes text When it arrives (llm word by word), and send out audio under lock. Voxtream implements the latter: it ingests the word stream and generates audio frames continuously, eliminating input buffering while keeping frame calculations low. The architecture explicitly targets the first word, not just steady-state throughput.
How does voxtream start speaking without waiting for future words?
The core skill is Dynamic phonemes look easy internal Incremental Phonema Transformer (PT). pt possible peep 10 phonemes Stable rhythm, but It’s not waiting For this case; generation can begin immediately after the first word enters the buffer. This avoids fixed browsing windows that add an onset delay.
What is the model stack under the hood?
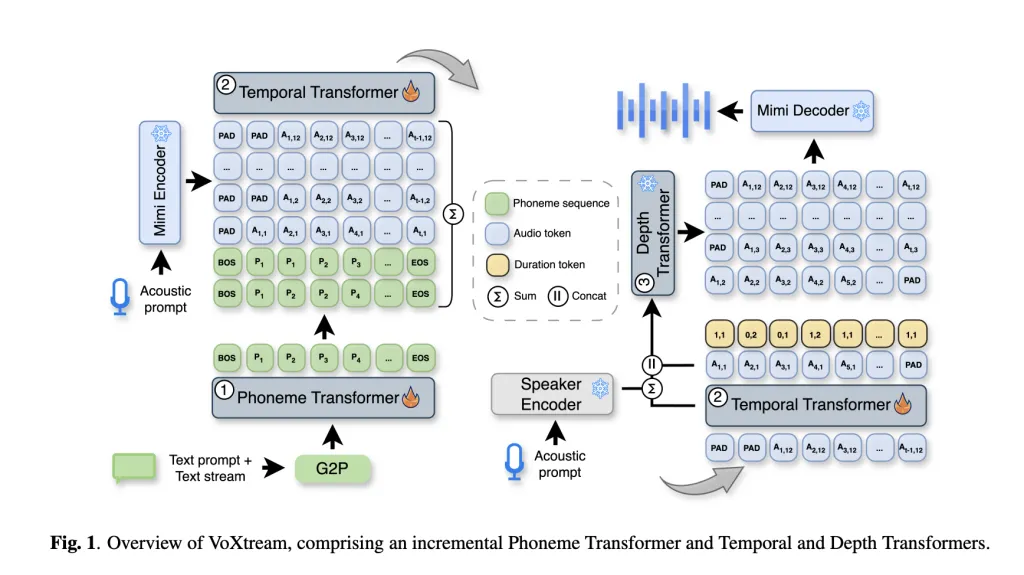
Voxtream is a Single, fully automatic (AR) Pipeline with three transformers:
- Phoneme Transformer (PT): Decoder only, increment; dynamic appearance ≤10 phonemes; phoneticization at word level by g2pe.
- Temporal Transformer (TT): AR predictors Boobs Codec Semantic Token More Duration token This encodes the alignment of monotonic phonemes to the plaintiff (“arear/go” and phonemes per frame of {1, 2}). Mimi runs 12.5 Hz (→ 80 ms frame).
- Depth Transformer (DT): Remaining AR generators for AR StatementTT output as condition redimnet Spokesperson Embed Zero shot Sound prompt. The MIMI decoder reconstructs the waveform frame frame by frame, so that it can transmit continuously.
MIMI’s streaming codec design and dual stream tokens have been well documented; Voxtream uses its first codebook as a “semantic” context, and the rest of the codebook is used for high-fidelity reconstruction.
Actually, is it actually fast? Or “fast on paper”?
The repository includes a Benchmark scripts Both are measured fpl and Real-time factor (RTF). exist A100Research Group Report 171 MS / 1.00 RTF No compile and 102 ms / 0.17 RTF Compile; RTX 3090,,,,, 205 MS/1.19 RTF Not compiled and 123 ms / 0.19 RTF Compile.
How about compared to today’s popular streaming baselines?
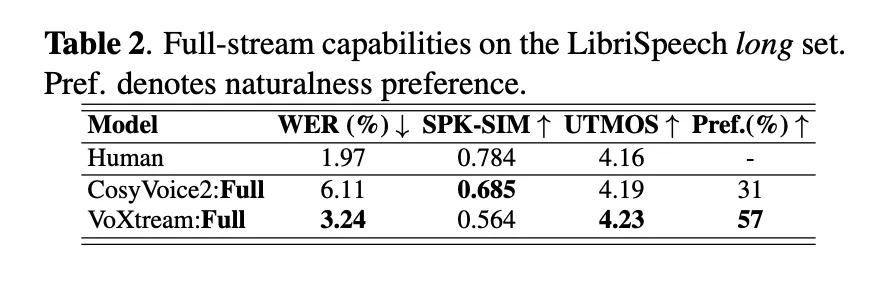
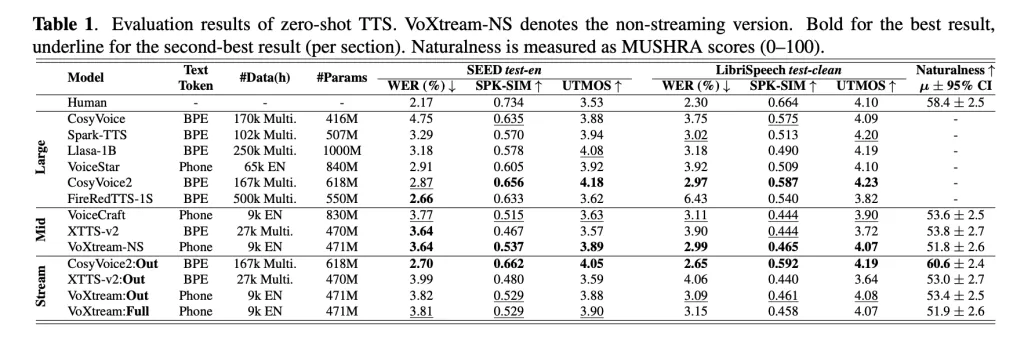
Research group evaluation Short form output stream and Full flow plan. exist librispeech-long Full stream (text arrives), voxtream display Lower than Cosyvoice2 (6.11%) (3.24%) (3.24%) and Important natural preferences voxtream for audience research (p≤5E-10), while cosyvoice2 scores higher on speaker similarity – matching its stream-matching decoder. At runtime, Voxtream has the lowest FPL in the compared public flow systemand run with compile > 5× faster than real time (RTF≈0.17).
Why does this AR design beat the diffusion/traffic stack when it occurs?
The diffusion/flow vocoder will usually be in pieceso even if the interweaving of text audits is clever, Vocoder applies flooring on the first packaging delay. Vikstrim keeps AR and framework synchronization at each stage– PT→TT→DT→MIMI decoder – so the first 80 ms A packet appears after passing through the stack instead of a multi-step sampler. Briefly investigate methods of prior interweaving and splitting and explain how NAR traffic matching decoder Used in IST-LM cosyvoice2 Despite its strong offline quality, it still hinders low FPL.
Do they have a lot of data coming here, or something smaller and cleaner?
Voxtream trains are on ~9k hours of mid-term corpus: Approximately 4.5kh Emilia and 4.5kH Hifitts-2 (22 kHz subset). team diagnosis To delete multi-speaker clips, Filter transcripts Use ASR and apply explain Drop low-quality audio. Everything is resampled 24 kHz,The dataset card illuminates the preprocessing pipeline and alignment artifacts (MIMI token, MFA alignment, duration tags and speaker templates).
Are the title quality indicators lifted outside the cherry-picked clips?
Table 1 (zero beats) shows Voxtream in wr,,,,, UTMOS (MOS predictor) and Similarity of speakers Passed through Seed-TTS Test and Librispeech Test Cleaning;The research team is also running Absolute:Add to CSM depth transformer and Speaker encoder There is no obvious fine relative to the baseline of stripping, which can improve the similarity. This subjective study used a Mushra-like protocol and a phase 2 preference test tailored for the entire basin.
Where is this place to land in the TTS landscape?
According to the research paper, it locates voxtream at the nearest Intertwined AR + NAR Vocoder Methods and lm-codec Stack. The core contribution is not a new codec or megamo model, but Delay-centric AR layout More Duration Alignment reserve Input Stream. If you set up a live agent, the important tradeoff is clear: a small drop in speaker similarity vs. Lower fpl level NAR sound encoder under full-stream conditions is larger than a larger NAR sound encoder.
Check Paper, model about hugs, github page and Project page. Check out ours anytime Tutorials, codes and notebooks for github pages. Also, please stay tuned for us twitter And don’t forget to join us 100K+ ml reddit And subscribe Our newsletter.
Talk to us about content partnerships/promotions on Marktechpost.com
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
🔥 (Recommended Reading) NVIDIA AI Open Source VIPE (Video Pose Engine): a powerful and universal 3D video annotation tool for spatial AI