
 1005 Alcyon Dr Bellmawr NJ 08031
1005 Alcyon Dr Bellmawr NJ 08031
Researchers and organizations face significant challenges in a rapidly evolving landscape of large language models (LLM). These include enhanced inference capabilities, providing powerful multilingual support, and efficient management of complex open tasks. Although smaller models are generally more accessible and cost-effective, they are often underperformed compared to their larger counterparts. Therefore, there is an increasing emphasis on the development of medium-sized models that can effectively balance computational efficiency with strong inference and guidance and compliance capabilities.
The recent release of GLM 4 from Tsinghua University, especially the GLM-Z1-32B-0414 variant, effectively addressing these challenges. GLM 4 is trained on a large data set of 15 trillion tokens to provide reliable multilingual capabilities and incorporates innovative reasoning strategies called “thinking patterns.” This release positions GLM 4 as other well-known models such as DeepSeek Distill, QWQ and O1-Mini and is distributed under a widely respected MIT license. It is worth noting that despite its relatively medium parameter size of 32 billion, the performance of GLM 4 shows comparable performance to a large number of larger models, such as GPT-4O and DeepSeek-V3, which contains up to 671 billion parameters, especially in inference-centric benchmarks.
At the technical level, GLM-Z1-32B-0414 utilizes a wide range of high-quality training data, including synthetically generated inference tasks, to enhance analytical capabilities. The model integrates complex techniques such as rejection sampling and enhanced learning (RL) to improve performance in tasks based on agent-based tasks, encoding, feature calls, and search-driven problems. In addition, the changes in its “deep inference model” further improve this change by combining the cold start method with extended RL training, specifically targeting complex mathematical, logical and coding tasks. A feedback mechanism of pairwise ranking was adopted during the training period to improve the general reasoning effect of the model.
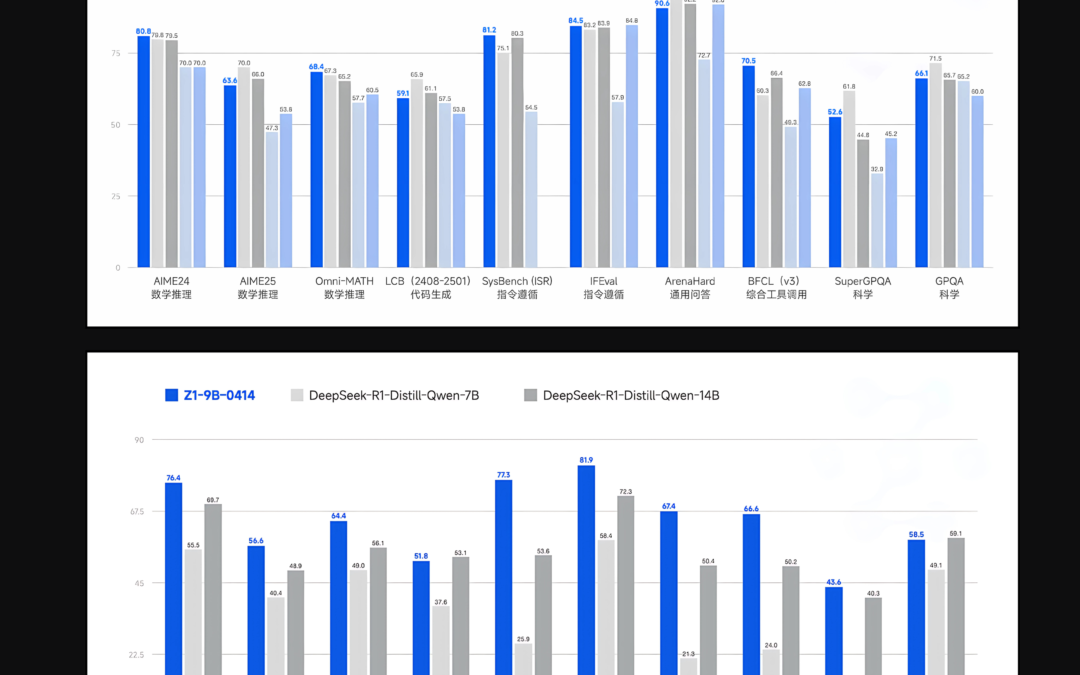
An advanced variant, GLM-Z1-RUMAINITION-32B-0414, introduces a novel approach called “reflection” that allows long-term reflective reasoning to solve open, complex queries, such as comparing AI-drien-driven Urban analysis. This variant combines advanced search tools with multi-objective reinforcement learning, which significantly enhances its utility in scenarios of research-intensive tasks and complex retrieval. Complementing with these larger models, the GLM-Z1-9B-0414 version has 9 billion parameters, providing powerful mathematical and general reasoning capabilities, demonstrating the practicality of smaller-scale models.


Performance data from benchmark evaluation highlights the advantages of the GLM 4 series. Specifically, GLM-4-32B-0414 shows reliable results compared to GPT-4O, DeepSeek-V3 and Qwen2.5-Max across multiple benchmarks. The GLM 4 scored an impressive 87.6 in the benchmarks followed by the IFEVAL directive. In task automation benchmarks such as tau bench, GLM 4 scored well in programs such as retail (68.7) and airline (51.2). For the question-asked task raised by the SimpleQA-evaluated search, the model scored 88.1. In addition, GLM 4 closely matches the performance of GPT-4O in the BFCL-V3 benchmark evaluation task, ensuring a total score of 69.6. In a practical code repair scheme, SWE-Bench was tested through a moat-free framework, with the success rate of GLM 4 at 33.8%, emphasizing its real value.
In summary, GLM 4 demonstrates itself as an effective family of language models, successfully bridging the performance gap between smaller, more accessible models and traditionally larger peers. The GLM-Z1 series, especially the 32B variant, embodies this balanced approach by providing strong inference capabilities while maintaining computational affordability. With the added benefits of its allowed MIT license, GLM 4 is positioned as a powerful tool for research and enterprise applications requiring high-performance AI solutions without the extensive computing overhead traditionally associated with larger models.
Check GLM-4-Z1-32B-0414 Model and Other models. All credits for this study are to the researchers on the project. Also, please feel free to follow us twitter And don’t forget to join us 90K+ ml reddit.
Asif Razzaq is CEO of Marktechpost Media Inc. As a visionary entrepreneur and engineer, ASIF is committed to harnessing the potential of artificial intelligence to achieve social benefits. His recent effort is to launch Marktechpost, an artificial intelligence media platform that has an in-depth coverage of machine learning and deep learning news that can sound both technically, both through technical voices and be understood by a wide audience. The platform has over 2 million views per month, demonstrating its popularity among its audience.
